A Very Brief Investigation of Using Finetuning To Interpret Wav2Vec 2.0
In recent years there has been an explosion in the use of foundation models in automatic speech recognition (ASR). In this post, I overview some brief experiments involving finetuning a specific foundation model – Wav2Vec 2.0 – for the task of ASR on the LibriSpeech-10hour dataset. The aim of this post is to show basic methods can be used as a first step in interpretting large models.
A Brief Overview of Wav2Vec 2.0
Foundation models are models that are trained using self-supervised learning on huge amounts of unlabelled data in a process known as pre-training. Self-supervised learning refers to the fact that the objectives foundation models are trained on during pre-training do not require human annotations of the training data. In the context of ASR-related tasks – where human annotation is notably expensive relative to other deep learning areas – this is hugely useful as it allows foundation models to be trained on many orders of magnitude more data than is the case with standard supervised learning of ASR systems. The idea is that by pre-training foundation models on huge amounts of audio data, the foundation models will learn useful, general representations. We can then further train foundation models on a downstream application of interest in a process called fine-tuning. Fine-tuning, therefore, can be seen as finding a way to utilise (and perhaps slightly modify) these powerful representations for the task at hand.
Wav2Vec2.0-Base (which I refer to as W2V for the remainder of this post) is a popular foundation model in the ASR community that was pre-trained on the full LibriSpeech 960-hour dataset of unlabelled speech data (Baevski et al., 2020). W2V has a specific structure and pre-training scheme that aims to allow it to learn useful representations. Structurally, the core W2V model consists of a CNN encoder that maps from raw waveforms to a sequence of latent speech representations and 12 masked transformer layers that turns these latent speech representations into contextual representations. W2V’s success as a foundation model is due to its training scheme. The model includes a quantizer that converts outputs from the encoder to discrete speech tokens from a learned codebook of speech tokens. This allows the model to be trained using a unique self-supervised loss. This loss combines a contrastive loss (whereby the model seeks to distinguish masked segments in the input speech waveform from distractor samples from an alternative speech waveform) and a diversity loss (that avoids codebook collapse by encouraging diversity in the learned codebook). The figure below is taken from the original W2V paper and illustrates this architecture.
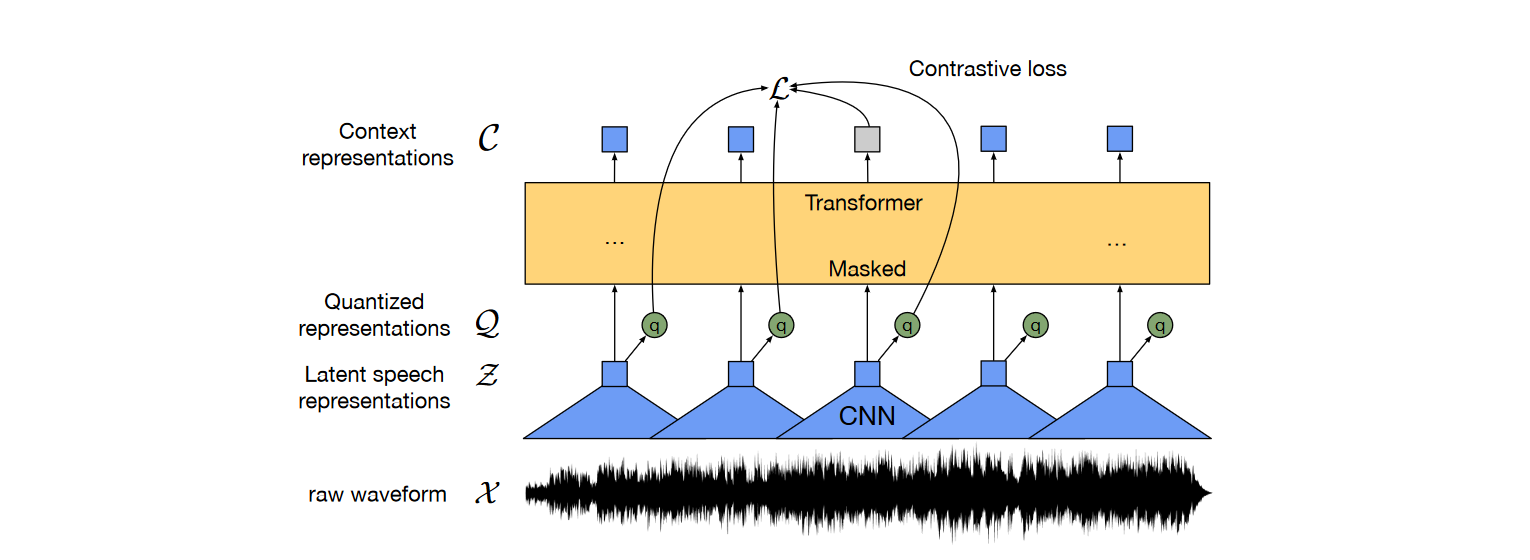
An output layer to project into the desired output space can then be placed on top of W2V such that we can fine-tune it for a downstream application of interest. For instance, when fine-tuning W2V for the task of ASR, this output projection will project into the space of possible tokens (such as characters, phones or morphs).
Fine-tuning Methodology
LibriSpeech is a dataset consisting of utterances and associated word-level transcripts. LibriSpeech contains both “clean” and “other” data, with “other” data consisting of, on average, more challenging utterances. In the following, I investigate fine-tuning W2V on a 10-hour subset of LibriSpeech consisting of 5 hours of “clean” data and 5 hours of “other” data. My validation set similarly mixes the two types of data and I report test word error rates (WERs) on a “clean” and an “other” test set separately. I train all models to output characters from a 30-character vocabulary consisting of the 26 standard characters, an ellipse, a <space> token to denote space between words, a <unk> token to denote an unseen character and a <blank> token for CTC decoding. Decoded strings of characters are turned into strings of words by taking the <space> token to denote word boundaries
In the following, all fine-tuning runs use Adam for 10 epochs with a tri-state learning rate scheduler that warmed up over the first epoch and decayed to 0 from the start of the 6th epoch while freezing the W2V module for the first 3 epochs. The learning rate warmed up to a maximum of 1e-4 and I used gradient clipping with a clipping value of 1. All following results are the average of three fine-tuning runs with different random seeds. Using this fine-tuning regime resulted in an average test WER (word error rate) of 10.71% on the clean utterances and 19.47% on the other utterances when fine-tuning all parameters in the W2V model. I refer to this as my baseline result. That we have achieved such a low WER despite only having 10 hours of supervised training data again speaks to the power of fine-tuning foundation models. Clearly, W2V has learned representations of input speech waveforms that are hugely useful in classifying spoken utterances.
Re-Initialising Layers
How, then, can fine-tuning help us interpret the internal computations performed by the W2V model? Well, we can fine-tune the model in a manner designed to isolate the role played by specific W2V components! For instance, it has been argued that that the pre-training scheme of W2V causes W2V to effectively function as a large autoencoder-style model (Pasad et al., 2022). This is to say that during pre-training, W2V’s early transformer layers learn at first to abstract away from inputs towards general representations before its later layers learn then to partially re-construct inputs in order to perform well at its contrastive pre-training task. If this hypothesis is true, we should expect re-initialising the final W2V transformer layers prior to fine-tuning to have minimal effect on the performance of the fine-tuned W2V model.
To test this, I followed Pasad et al (2021) and investigated re-initialising the final three W2V transformer layers. The table below shows my results.
| Layers Re-Initialised | Average Validation WER | Average Test WER – Clean | Average Test WER – Other |
|---|---|---|---|
| None (Baseline) | 13.87% | 10.71% | 19.47% |
| 12 | 14.30% | 10.93% | 19.58% |
| 11, 12 | 13.80% | 10.82% | 19.45% |
| 10, 11, 12 | 15.34% | 11.49% | 21.18% |
This table shows that the WERs resulting from re-initialising just the twelfth W2V layer and the eleventh and twelfth W2V layers are sufficiently close to the baseline WERs that it is hard to argue that the WERs are meaningfully distinct . This suggests that these final two pre-trained layers contain barely any useful information for ASR, and we can view fine-tuning them on Librispeech as “overwriting them”. The table also illustrates that WERs increase by a small but meaningful amount when re-initialising the tenth, eleventh and twelfth layer. The fact that test WERs increase in this case implies that the pre-trained 10th layer does contain some ASR-relevant information, albeit only to a certain degree given that test WERs have only worsened slightly. The upshot of these results is that the final 3 transformer layers all must change heavily during fine-tuning (especially the final 2 layers that appear to be almost completely overwritten) else we would see large increases relative to the baseline when we re-initialise them. These results are consistent with the aforementioned hypothesis and illustrate how some easy fine-tuning can be used to quickly empirically test an interpretablity hypothesis.
Fine-Tuning Using W2V As A Feature Extractor
Often, it is of interest to fine-tune a completely frozen foundation model. One reason we might want to do this is to reduce the number of parameters we need to fine-tune. If we only have a small amount of data for our downstream task, for instance, reducing the number of tuneable parameters is crucial to avoid overfitting. When freezing a whole foundation model, we can view the foundation model as a feature extractor that has learned in pre-training how to extract features from input speech waveforms that are generically useful for downstream applications. In an interpretability setting, using a foundation model as a feature extractor allows us to investigate the applicability of the model’s representations to particular tasks of interest, providing insight into what is represented at specific layers of the model. Note that this idea is related to the idea of the logit lens and its variations in language modelling (Belrose et al., 2023).
I investigated fine-tuning a model consisting of a frozen W2V module and a 3-layer bi-directional LSTM with a hidden dimensionality of 1024. This corresponds to teaching the LSTM to recognise spoken utterances using the features produced by the frozen W2V. I investigated fine-tuning such an LSTM that took as inputs the representations at each of the layers of a frozen W2V model. The figures below show the resulting word error rates.
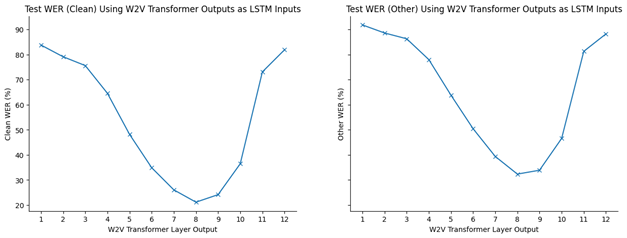
These figures provide additional evidence for the hypothesis that W2V has learned autoencoder-style behaviour. Specifically, they illustrate that using the final transformer layer outputs as features results in poor WER which we expect given that these final layers are adapted to the specific contrastive pre-training task. Likewise, using outputs from the early transformer layers results in poor WERs which we would expect given that these layers are still building towards useful generalised representations of speech waveforms. Both clean-WER and other-WER are minimised when using outputs from layer 8. This makes sense when we consider that this is the rough layer at which general representations have been constructed by, but before these general representations are modified for the pre-training task.
Summary
In this blog post I have illustrated how fine-tuning can be used as a basic tool when interpretting foundation models. Specifically, I have shown how some basic fine-tuning experiments can be used to perform rudimentary empirical tests of the hypothesis that Wav2Vec 2.0 leans to function as an autoencoder-style model. Note that these fine-tuning experiments primarily seek to rapidly falsify hypotheses, and that positively validating them would require the use of tools such as probing.
References
2023
- Eliciting Latent Predictions from Transformers with the Tuned Lens2023
2022
- Layer-wise Analysis of a Self-supervised Speech Representation Model2022
2020
- wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations2020
Enjoy Reading This Article?
Here are some more articles you might like to read next: